In the realm of software engineering, managing complexity is an ongoing challenge, especially as systems scale up and evolve. One modeling tool we can employ for this objective is aggregates. These powerful constructs provide a structured approach to organizing domain objects, enforcing consistency, and encapsulating business logic within bounded contexts.
In this article, we delve into the fundamental concepts of Aggregates, exploring their significance, structure, and role in designing robust domain models. Drawing insights from Eric Evans’ principles and real-world examples, we illuminate the rationale behind Aggregates and their essential contribution to building successful software systems.
Let’s embark on this voyage into the heart of Domain-Driven Design, where Aggregates reign supreme as guardians of consistency, integrity, and coherence within our software systems.
Table of contents
Open Table of contents
Why do we need Aggregates?
The Challenge
It is difficult to guarantee the consistency of changes to objects in a model with complex associations. Invariants need to be maintained that apply to closely related groups of objects, not just discrete objects. Yet cautious locking schemes cause multiple users to interfere pointlessly with each other and make a system unusable.
- Eric Evans
Since we aim to maintain the success of our systems, we require some modelling techniques to ensure that successful systems do not spiral out of control due to the increasing complexity of models arising from operational scaling and development.
Aggregates are concepts that maps easily to code and help us to keep code cohese and decoupled.
What are Aggregates?
In Domain-Driven Design (DDD), aggregates are clusters of domain objects treated as a single unit for data changes. Each aggregate has a root and a boundary. The boundary defines what is inside the aggregate, while the root is a single specific Entity contained within it.
They are named using an “Ubiquitous Language,” terms and nouns defined by Domain Experts and business people.
Thus, an Aggregate is:
- Part of the domain and its language: Aggregates represent concepts from the Ubiquitous Language.
- Artificial boundaries around closely related models: These boundaries partition the domain model into closely related groups, structuring your code and ensuring maintainability increasing decoupling.
- A unit of consistency: entities and value objects within an aggregate should be updated in a transaction. Additionally, specific rules called invariants guarantee that aggregates remain in a consistent state.
- A unit of concurrency: it ensures consistency even under high external pressure. With successful products, numerous concurrent accesses to aggregates are expected.
- A unit of distribution: Aggregates’ parts should be kept close together since they interact frequently, ensuring cohesive code.
Let’s attempt to identify some Aggregates while modeling a simple E-commerce Order Process:
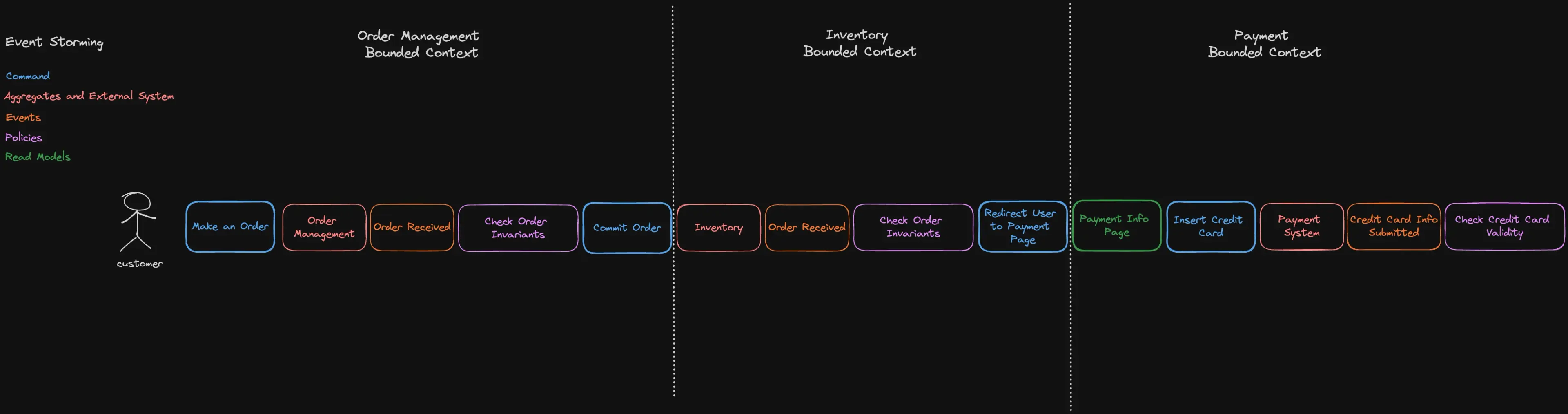
In this example, a customer places an order, which then undergoes validation and is eventually confirmed. Subsequently, the Inventory System verifies availability and other rules before redirecting the user to the payment page, and so forth. By tracking the events that can occur during this User Journey, we can identify three bounded contexts:
- Order Management
- Inventory
- Payment
Unfortunately, before going on talking about aggregates, we need to introduce another concept
Bounded Context
In Domain-Driven Design (DDD), a Bounded Context is a specific area within a software system where a particular model or terminology applies consistently.
Eric Evans, in his book “Domain-Driven Design: Tackling Complexity in the Heart of Software,” provides the following definition:
Bounded Context delimits the applicability of a particular model so that team members have a clear and shared understanding of what has to be consistent and how it relates to other contexts. Within that context, work to keep the model logically unified, but do not worry about applicability outside those bounds.
To elaborate:
- Delimits Applicability: A Bounded Context defines the scope within which a particular model, set of concepts, or language is valid and applicable. It helps delineate where certain terms, rules, and concepts hold true and have significance.
- Ensures Consistency: Within a Bounded Context, all concepts and terms should be consistent and have a clear, agreed-upon meaning among team members. This consistency aids in communication and understanding within the team.
- Defines Relationships: Bounded Contexts also define relationships between different models or concepts. They clarify how the models within the context interact with each other and how they relate to models in other contexts.
- Encourages Logical Unity: While each Bounded Context has its own specific model and terminology, it should maintain logical unity within its boundaries. This means that within the context, the model should be cohesive and make sense as a whole.
- Acknowledges Differences: Bounded Contexts recognise that different parts of a system may have different models and interpretations of concepts. They allow for flexibility and adaptation to varying requirements and perspectives within different parts of the system.
Overall, Bounded Contexts help manage complexity by providing clear boundaries for models and concepts within a system, enabling teams to work effectively and collaboratively while ensuring consistency and logical coherence within specific areas of the domain.
Without too much approximation, you can consider Bounded Contexts as Aggregates containers.
Ok let’s go back to the example: inside the Order Management Bounded Context we spot the first candidate to be an Aggregate:
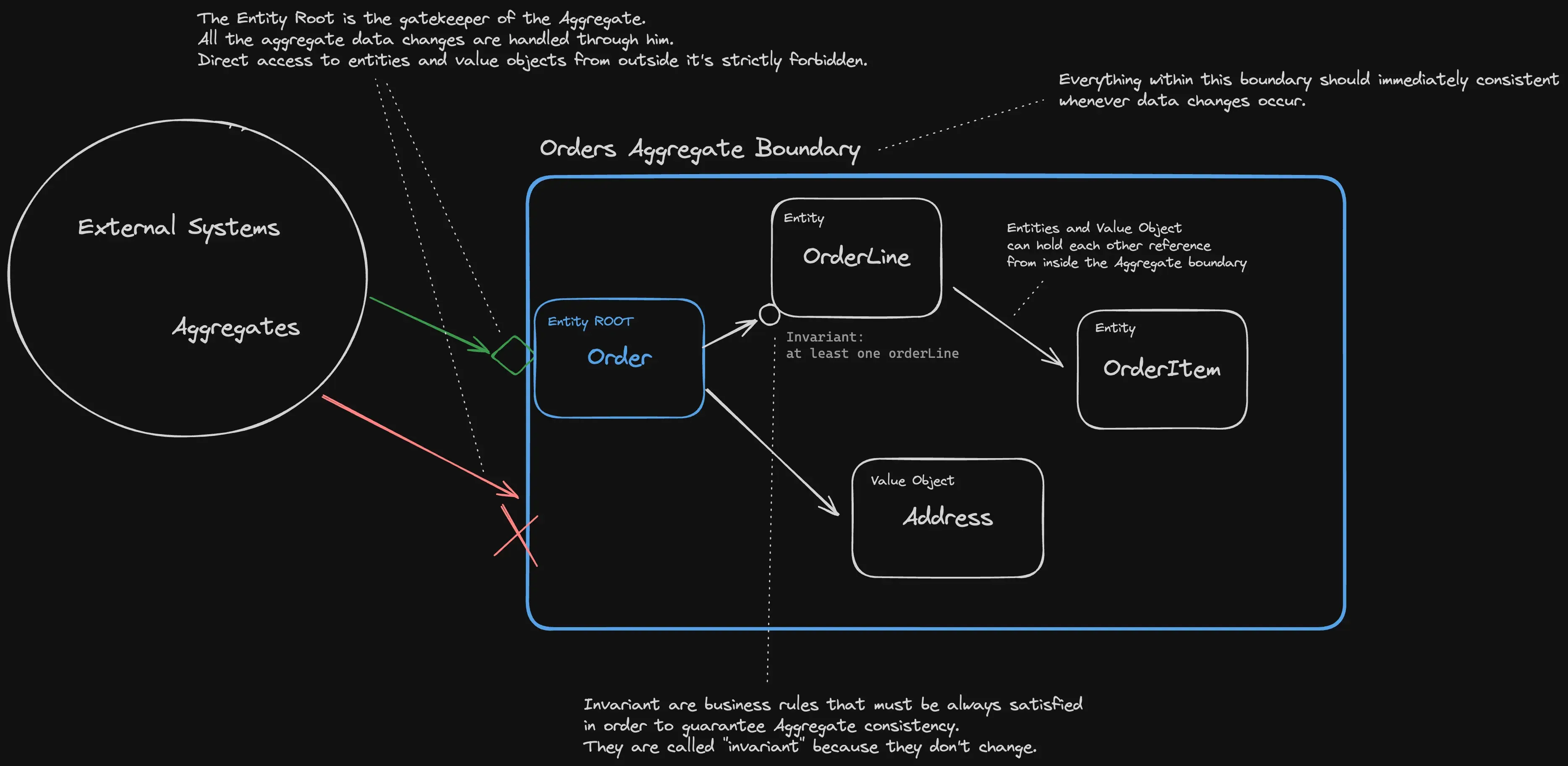
Orders define a Boundary, inside it you can find
- Order: the Entity Root
- at least one Entity, Order Line
- the Value Object: Customer Address
- the Entity OrderItem, linked to Order Line
Those domains object can be implemented in code as classes and modules, the entire aggregate can be a Microservice, a namespace, a Package, a Class or a Module.
Each Aggregate should be as big as needed as small as possible.
The difference between Entities and Value Object it outside the scope of this post, but you can find it on the internet with a bit of research.
What makes the aggregates a special concept is that it must adhere to the following aggregate rules:
1. Aggregates internals are accessible ONLY through it’s ROOT Entity
References to Aggregate internals from the outer world are strictly forbidden!
You can only access Aggregate internals (entities and value objects) from the inside or by passing through the Entity Root.
To be more clear, Let’s illustrate this with an example where this concept is violated:
// We get an Account aggregate somewhere
Account account = repository.get();
// Reference given to the outer world
AccountToken token = account.getAccountToken();
// Data changes not guarded by the root
token.invalidate();
// Invariant checked outside the aggregate
Challenge challenge = Challenge.fromRequest(request);
if (!account.getToken().confirm(challenge)) {
throw new Exception("Challenge invalid.");
}
Instead, The preferable approach:
// We get an Account aggregate from the repository
Account account = repository.get();
// Data changes handled by the aggregate root
account.invalidateToken();
// Give out an immutable value instead
ReadOnlyToken readOnlyToken = account.getReadOnlyToken();
// Invariant checked inside the aggregate
Challenge challenge = Challenge.fromRequest(request);
account.confirm(challenge);
// Eventually throws a domain exception2. Aggregate integrity rules must be ALWAYS granted
An aggregate should represent a cohesive cluster of related domain objects subject to consistency rules and business invariants.
2.1 Integrity granted via Transactional Consistency
- Transactional consistency refers to the guarantee that the state of data remains consistent before and after a transaction, ensuring that data changes occur atomically and either all changes are committed or none are.
- It ensures that a series of operations performed within a transaction leave the system in a valid state, adhering to all constraints and rules.
Does Every Aggregate need Transactional Consistency?
Not all aggregates necessarily require transactional consistency. Some aggregates may deal with read-only data or data that can be updated independently without strict transactional boundaries.
For example, consider a reporting aggregate in an analytics system that aggregates data from multiple sources for generating reports. This aggregate may not require strict transactional consistency because the data it operates on is primarily read-only or asynchronously updated. It still represents a logical grouping of domain objects for a specific purpose within the domain, even though transactional consistency might not be a primary concern.
In summary, while transactional consistency is often a consideration in designing aggregates, it’s not a defining characteristic. Aggregates are primarily about grouping related domain objects to enforce consistency and encapsulate business logic, and they can exist even when strict transactional consistency is not required.
However, for some aggregates, maintaining data integrity and enforcing business rules are crucial.
How to Ensure Transactional Consistency?
Transactional consistency, for instance, can be enforced at the database level having ACID transaction:
- ACID Properties:
- Atomicity: All operations within a transaction are treated as a single unit of work. Either all operations succeed, and the transaction is committed, or none of them are, and the transaction is rolled back.
- Consistency: The database remains in a consistent state before and after the transaction, enforcing all constraints and rules.
- Isolation: Transactions are isolated from each other until they are completed, preventing interference between concurrent transactions.
- Durability: Once a transaction is committed, its changes are permanently saved and survive system failures.
2.2 Integrity granted via Business Invariant
An invariant, in the context of Domain-Driven Design (DDD), refers to a condition or rule that must always be true within a specific domain model or within an aggregate. Invariants define the constraints that govern the valid state of the domain objects. These invariants are essential for maintaining data integrity and ensuring that the domain model adheres to the business rules.
Let’s consider an example of an aggregate called Order in an e-commerce domain.
public class Order {
private String orderId;
private List<OrderItem> orderItems;
private boolean isPaid;
// Constructor, getters, setters, and other methods
public void addItem(OrderItem item) {
// Business rules validation
if (!isPaid) {
orderItems.add(item);
} else {
throw new IllegalStateException("Cannot add items to a paid order.");
}
}
public void markAsPaid() {
// Business rules validation
if (!isPaid) {
isPaid = true;
} else {
throw new IllegalStateException("Order is already paid.");
}
}
}
public class OrderItem {
private String productId;
private int quantity;
private BigDecimal price;
// Constructor, getters, setters, and other methods
}
In this example:
Orderis the aggregate root, representing an order in the e-commerce system.OrderItemrepresents an item within an order.- The
Orderaggregate enforces the following business invariant viaisPaidflag: “Once an order is paid, no further modifications to its items should be allowed.”
Business rule is ensured through the addItem and markAsPaid methods:
addItem: Ensures that items can only be added to an order if it’s not yet paid. This prevents adding items to an order that has already been paid for.markAsPaid: Marks the order as paid, preventing any further modifications to its items.
Both operations are encapsulated within the Order aggregate, ensuring that the order’s state transitions are consistent within a transaction boundary. This ensures that any changes made to the Order maintain data integrity.
Invariants are crucial for maintaining the consistency and correctness of the domain model, and they play a significant role in designing aggregates and defining business logic.
Now that we understand what an Aggregate is, let’s attempt to identify a second one within the Inventory bounded context.
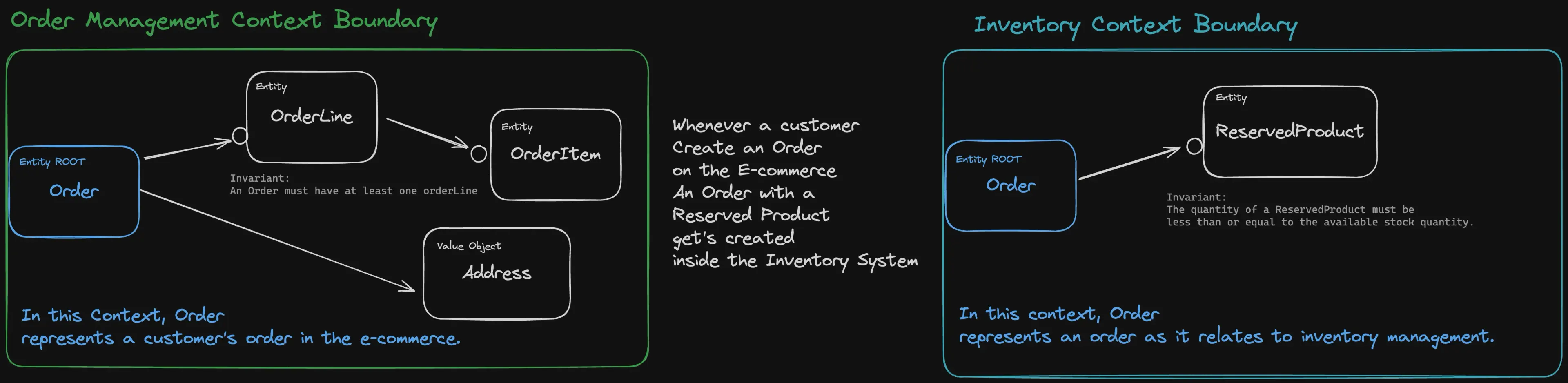
It appears that orders are also received by the Inventory system, but this time, they seem to be slightly different. Even though both aggregates share the same name and depend on each other, utilizing the same value objects and entities, they are indeed two distinct aggregates. In fact, another important rule concerning aggregates is the identity rule:
3. Identity Rule
Two identical aggregates are actually distinct, distinguished by an identity.
The two aggregates are indeed distinct; however, communication between them should be eventually consistent!
As Eric Evans says:
Any rules that spans Aggregates will not be expected to be up-to-date at all times. Through event, processing, batch processing, or other update mechanism, other dependencies can be resolved within some specified time.
Final Thoughts and Recap
In conclusion, Aggregates stand as essential constructs within Domain-Driven Design, providing a structured approach to organizing domain objects, enforcing consistency, and encapsulating business logic. Through our exploration, we’ve gained a deeper understanding of Aggregates and their significance in building robust and scalable software systems.
We began by defining Aggregates as clusters of associated objects treated as a single unit for data changes, with each aggregate having a root entity and a boundary that defines its scope. Understanding Aggregate rules, such as encapsulation and maintaining consistency, is crucial for effective domain modeling.
Furthermore, we delved into practical examples to illustrate the importance of adhering to Aggregate principles, highlighting the pitfalls of violating encapsulation and the benefits of enforcing consistency and business rules within aggregates.
Moreover, we explored the concept of Bounded Contexts and their relationship with Aggregates, emphasizing the need for clear boundaries and cohesive models within specific contexts.
In our journey, we’ve discovered that while Aggregates may share common elements across different contexts, they remain distinct entities with their own identity and purpose. Communication between aggregates should be eventually consistent, ensuring data integrity and coherence within the system.
In essence, Aggregates serve as pillars of strength in the ever-evolving landscape of software engineering, enabling teams to navigate complexity with confidence and clarity. By embracing the principles of Domain-Driven Design and harnessing the power of Aggregates, developers can build resilient, adaptable, and scalable software systems that meet the evolving needs of users and stakeholders alike.
See you in the next post! ;)